devblogs
Instancing: The GPU feature made for voxels
Instancing is the GPU’s hardware-native solution to the many-alike problem — foliage, crowds, voxels. Yet the Vulkan Tutorial skips it entirely, and the official coverage that does exist lives inside a large tutorial engine. This devblog covers instancing from the ground up, targeted at readers who just finished the Vulkan Tutorial. Instancing is the first major optimization I have applied to VOXEL EXPLORE, my new Vulkan/Rust voxel renderer project.
In this article, I will discuss:
- What instancing is on a high-level, and why instancing is essential for voxel rendering.
- How instancing improves the VOXEL EXPLORE chunk layout so I can draw more voxels. My new chunk layout can support 435 times more voxels per chunk, thanks to instancing.
- How to implement instanced rendering, intended for readers who followed the Vulkan Tutorial (C++ or Rust) and got at least as far as the chapter on indexed draws.
- An alternative approach to implementing instancing in Vulkan worth mentioning, compared.
- Several ideas I have on how to improve the chunk representation even further for even better amortized voxel memory density.
As a bonus, I will show off using RenderDoc to inspect and validate Vulkan instance buffer state and count bytes, in section 3.
1. Why use instancing for voxels?
The GPU’s graphics pipeline invokes a vertex shader for each Vertex in the vertex buffer. This means that whatever struct is used to represent a Vertex has two jobs:
- Serve as the discrete parallelization unit for geometry data sent to the GPU.
- Encode the information needed to represent geometry, including world position, normals, and any relevant texture indices, coloring, or material info.
Instancing helps in the situation where these two priorities come into conflict. If you have many repeated instances of the same or similar 3D form, but have a heavy Vertex struct needed to represent the necessary geometric information, then you have memory-intensive but information-sparse structure. Voxels are precisely this situation. The VOXEL EXPLORE Vertex struct looks like this:
// geometry_primitives.rs
pub struct Vertex {
pub position: [f32; 3],
pub color: [f32; 3],
pub normal: [f32; 3],
}
Even such a lean struct does have a non-neglible memory cost. It is $4 * 3 * 3 = 36$ bytes. That is just simply too big. Remember from the README.md that voxel geometry memory demand scales cubically with volume. If we want to budget memory for billions of voxels and have space to spare, then this just won’t do. If a Vertex uses 36 bytes, and a cube (with index buffering) uses 24 Vertex’s (four per face), then we need $24 * 36 = 864$ bytes for a cube. This is at least 864 times more than ideal. Especially in volumetric terms, this is a huge overhead for just one voxel. It implies large worlds would have abysmal loading times. And, that moving around any nontrivially-sized voxel environment even just at walking speed would incur periodic breaks and pauses, particularly in sparse environments where techniques such as occlusion culling don’t apply.
Now, for the record, rest assured that it is rare that voxels fill a voxel world totally homogenously; a standard prior is that voxels tend to cluster, and that most space is empty. So, the standard approach is to segment the world into fixed-size chunks and apply some intelligent sparse chunk-selection algorithm. Because I have set my chunk memory size to 64 KiB to align with Windows’ minimum allocation size, then this implies we get $65536/864 \approx 75$ voxels in a chunk. This is peanuts. Such a sparse chunk-loading algorithm would need to somehow bear most of the load to achieve realtime rendering performance, and we would need to cap render distance to tragic extremes.
While indeed some intelligent chunk-loading approach is needed regardless in any voxel renderer, that component is out of scope of this devblog. That’s because, first, I want to explore more efficient chunk representations so that we can do better than 75 voxels per chunk (or about a 4x4x4 voxel volume). Doing so should dramatically improve the constant factor of the number of loads needed for a desired render distance, regardless of how smart the chunk-selection algorithm is. If we were to double this side length, then our densest 3D voxel structures would need $2^3=8$ times fewer chunk loads.
Enter instancing. Instanced drawing is the way to decouple vertex geometry from its position in Vulkan, which is essential for optimizing amortized memory spent on voxels. First, we group Vertex’s into one conceptual shape (in our case, naturally, that conceptual shape is one voxel). Then, upon draw, the vertex shader will invoke for every vertex in the group, once per set of instance parameters in the instance buffer. The instance buffer is created and populated just like a vertex buffer and is bound to the VkCommandBuffer using the very same vkCmdBindVertexBuffers call that the vertex buffer already uses. Think of instancing as like a virtual, hardware-accelerated nested for-loop for our draw call. The outer loop advances the per-instance parameters, and the inner loop advances the per-vertex parameters. This means that the vertex shader gets additional per-instance parameters which advance at a different input rate than the per-Vertex parameters. The idea is that this saves us quite a bit of memory if the memory required per instance parameter set is low. Thanks to vertex data reuse, the instance buffer capacity–not the vertex buffer capacity–is the limiting variable determining our voxels : chunk ratio.
2. VOXEL EXPLORE chunk layout
Before I get to the technical instancing tutorial, this section will overview how I have applied instancing for the new VOXEL EXPLORE project. VOXEL EXPLORE uses chunks to represent voxel world data. A chunk is a fixed-size block of voxel data representing a cubic region of world space, analogous to how pages are a fixed-sized block of memory for file data in a filesystem. This is the data sent to the GPU for rendering, either directly to the graphics pipeline for rendering or to a compute pipeline for preprocessing (culling, compacting, cached renders, etc). The VOXEL EXPLORE project is new and doesn’t currently have a geometry-preprocessing pipeline yet, so right now it just renders the chunk directly–but the instancing technique and the principles discussed in this article apply regardless.
Let’s prime the Vertex struct given above for instancing by decoupling material attributes from position data. Observe that it is redundant for both whole chunks and voxel instances to carry absolute position information. Might as well outsource absolute world-position to the chunk-level attributes, since it is sparse and would need that information anyway, and have each instance carry relative offset only. This architecture gives us bonus memory savings if, for each position axis x, y, and z, we reduce the max number of representable offsets from ‘anywhere in the world’ (requiring a whopping four bytes each) to just ‘side length of the chunk’. While we are at it, let’s also constrain chunk offsets to whole integers, since smaller voxels should look just fine at integer offsets anyway and because we do not want to splurge precious bits on a floating-point mantissa we could represent just once in the chunk-level attributes.
Here’s a convenient mathematical coincidence. If we afford 2 bytes per instance position vector, then the number of representable offsets (5 bits for each x, y, z position, plus one unused bit) is $(2^5)^3=32768$ representable offsets. Well, that is exactly equal to the number of 2-byte position vectors we could store in one chunk of the chosen allocation size, $64KiB / 2 bytes = 65536 / 2 = 32768$ voxels. This means each voxel can inhabit anywhere in the chunk, and that anywhere or everywhere in the chunk can be inhabited by a voxel. If we used fewer bytes per instance, then we wouldn’t be able to place voxels arbitrarily in a chunk’s associated world-space volume. Conversely, affording more bytes per instance (say, 3 bytes) would allow $2^{8*3} \approx 16M$ representable offsets, far exceeding the 32768 slots in a 64KiB chunk–wasted resolution. So, the 2-byte representation perfectly balances chunk configurability and chunk fill-ability. And, it is an enormous upgrade from 75 voxels.
A GPU’s VRAM has multiple competing uses: cached renders, preprocessed geometry–and, staging these raw chunks for culling, compacting or rendering. Denser chunks mean fewer chunks needed to cover the same world volume, which means faster world loading and more headroom for realtime voxel updates and world-activity.
A note on chunk design. If we wanted chunks to use a 1-hot, dense matrix representation, then we could use as little as one bit per voxel. However, that would imply that empty space would constitute one instance, and we would be burning gpu wavefronts on ~30k voxels worth of empty space in chunks that may have as few as 1 voxel in them. This would not be acceptable in practice. Ideas for how to further improve the chunk design–including what could be done with the 1 currently unused bit per instance offset vector–are shared in section 5.
3. Implementing instancing
To implement instancing in a Vulkan app, you need to:
- Have a set of vertex geometry to instance, and a dedicated type for instance parameters. In my case, the instance parameters are a
u16of packed position data. - Create an instance buffer and fill it with this instance data.
- Set up the graphics pipeline to accept an instance buffer binding. This is done together with the vertex buffer.
- Bind the instance buffer–again, together with the vertex buffer–to the
VkCommandBufferduring recording, and draw. - Update the vertex shader to accept and interpret the instance data.
This section will cover all of these steps. And as bonus, I’ll show how to inspect the changes to API state in RenderDoc and validate buffer memory layout.
Note that this tutorial is in Rust code. However, the concepts translate to C++ in a straightforward way. I will explain anything Rust-specific worth noting.
All of these edits can be reviewed in the diff of the tagged commit e4cde3c in tmasj/voxel-explore.
The VoxelInstanceParams type
My instance type is a struct that simply wraps a u16.
// geometry_primitives.rs
#[repr(C)]
#[derive(Copy, Clone, Debug)]
pub struct VoxelInstanceParams(u16);
unsafe impl bytemuck::Pod for VoxelInstanceParams {}
unsafe impl bytemuck::Zeroable for VoxelInstanceParams {}
impl VoxelInstanceParams {
pub fn new(v: Vec3) -> Self {
let cast = |float: f32| (float.round() + 0.0001) as u16 % 32;
let (r5, g5, b5) = (cast(v.x), cast(v.y), cast(v.z));
return Self((r5 << 11) | (g5 << 6) | (b5 << 1));
}
}
For any non-primitive types I pass to the shader, including Vertex, I make sure they are annotated with #[repr(C)]. In C++, this doesn’t apply, but in Rust, struct attributes do not have a definite layout, by default. Rust permits the compiler to abstract how to physically lay out normal structs in memory. This default behavior would create issues if we need predictable attribute offsets when we create VkVertexInputBindingDescriptions for the VkPipeline, so I use #[repr(C)] to ensure the layout is predictable. Additionally I mark the type as “POD” or “Plain Old Data” using the Pod trait Rust bytemuck library, mostly just for fun.
The Vec3 in the new() constructor is the glam::Vec3 Rust-analogue of a Vec3 in the C++ glm library.
Now, we need some geometry to display.
Loading an instance buffer
I make a procedural voxel spiral at the top of the app’s event loop, because that is where I keep “game-world” data.
// game.rs > impl GameGlobal
fn procedural_sculpture_75voxel(self: &Self) -> Vec<VoxelInstanceParams> {
let mut pos = Vec3 {
x: 2.,
y: 1.,
z: 0.,
};
let mut voxels = vec![];
let rotation = Mat3::from_rotation_y(0.7);
for i in (0..75) {
voxels.push(VoxelInstanceParams::new(pos + (i as f32 * 0.4) * Vec3::Y));
pos = rotation * pos;
}
return voxels;
}
Then, I load this data into a VkBuffer indirectly using a staging buffer similar to the way the Vulkan Tutorial explains here. The difference is, I don’t use just a plain VkBuffer. I developed a struct to encapsulate allocation, track the lifecycle of memory and any host mappings, and cache length/offset information of the instance data in a DataManifest that I read off later when I draw. See AllocatedDeviceBuffer in vulkan/device.rs at commit e4cde3c for usage of the DataManifest type.
// game.rs > impl GameGlobal > event_loop(..., rendering: &mut RenderingFlow)
let voxels: Vec<VoxelInstanceParams> = self.procedural_sculpture_75voxel();
let mut instance_buffer = rendering.new_instance_buffer_device_local(); // Same `VkBufferCreateInfo` and memory properties as a device-local vertex buffer
rendering.load_data_via_staging_buffer(&voxels, &mut instance_buffer);
In addition to this instance buffer, we need vertex and index buffers filled with the data needed to render one voxel. I build these buffers procedurally, like the the instance buffer, using the vertices() and indices() functions from the Voxel scheme below:
pub struct Voxel {
pub origin: Vec3,
pub color: [f32; 3],
}
impl Voxel {
pub fn new(origin: Vec3, color: [f32; 3]) -> Self {
Self { origin, color }
}
pub fn faces(&self) -> [QuadCCW; 6] {
let o = self.origin;
use Vec3 as V;
[
(V::ZERO, V::Z, V::Y), // -X
(V::X, V::Y, V::Z), // +X
(V::ZERO, V::X, V::Z), // -Y
(V::Y, V::Z, V::X), // +Y
(V::ZERO, V::Y, V::X), // -Z
(V::Z, V::X, V::Y), // +Z
]
.map(|(offset, former, latter)| QuadCCW {
position: o + offset,
former,
latter,
})
}
pub fn vertices(&self) -> Vec<Vertex> {
self.faces()
.iter()
.flat_map(|f| f.vertices(self.color))
.collect()
}
pub fn indices(&self, base: VertexIdx) -> Vec<VertexIdx> {
(0..6)
.flat_map(|i| QuadCCW::indices(base + i * 4))
.collect()
}
}
QuadCCW is my helper type for procedurally computing the four Vertex’s and six indices needed to produce a quad with normal that would agree with both a right-handed coordinate system and a counter-clockwise culling mode. Using Voxel I fill two other AllocatedDeviceBuffer’s with the vertex and index data, respectively, appropriate for displaying one voxel to be instanced. All three buffers will be passed to the app’s drawFrame() analogue for rendering and presentation.
Prepping the VkPipeline for binding
If we want to bind a new instance buffer during draw recording, we have to tell the VkPipeline that we plan to do this. It will simultaneously define host-side what “vertex input attributes” our vertex shader must declare and expect. We create a VkVertexInputBindingDescription associated with our new VoxelInstanceParams at binding position 1, since the Vertex type already uses binding position 0 (as well as, in our case, attribute locations 0, 1, and 2).
// geometry_primitives.rs
impl VoxelInstanceParams {
// pub fn new(...) { ... } // defined above
pub fn binding_description() -> vk::VertexInputBindingDescription {
vk::VertexInputBindingDescription::default()
.binding(1)
.stride(std::mem::size_of::<VoxelInstanceParams>() as u32)
.input_rate(vk::VertexInputRate::INSTANCE)
}
pub fn attribute_descriptions() -> [vk::VertexInputAttributeDescription; 1] {
let fourth = vk::VertexInputAttributeDescription::default()
.binding(1)
.location(3)
.format(vk::Format::R16_UINT)
.offset(std::mem::offset_of!(VoxelInstanceParams, 0) as u32);
return [fourth];
}
}
Unlike Vertex’s binding description, which uses the VERTEX input rate, we should use the INSTANCE input rate here. This means that the vertex input attributes in the vertex shader associated with the instance buffer will advance along with the gl_InstanceIndex built-in shader variable, rather than in lock-step with the gl_VertexIndex, which is what we want. gl_InstanceIndex will advance from the firstInstance up to the instanceCount passed into the CmdDraw function we use during VkCommandBuffer recording.
Style note: ash leverages straightforward function chaining to provide an idiomatic builder pattern for configuration structs. Speaking anecdotally, these builder configuration structs integrate pretty well with Rust’s borrow checker to protect against bad uses (such as mistaken premature deallocations). Helpful especially when these builders are fed into bigger builders.
Initially, I tried to use a VK_FORMAT_R5G5B5A1_UNORM_PACK16 in the attribute description since that would semantically fit my intent and would imply the vertex shader would automatically unpack the attribute into a vec4 for me (the fourth component just a 1-bit alpha channel). This was one of my best laid plans which went agley once I encountered this validation error:
"vkCreateGraphicsPipelines(): pCreateInfos[0].pVertexInputState->pVertexAttributeDescriptions->format (VK_FORMAT_R5G5B5A1_UNORM_PACK16) doesn\'t support VK_FORMAT_FEATURE_VERTEX_BUFFER_BIT.\n(supported bufferFeatures: VK_FORMAT_FEATURE_2_UNIFORM_TEXEL_BUFFER_BIT).\nThe Vulkan spec states: The format features of format must contain VK_FORMAT_FEATURE_VERTEX_BUFFER_BIT (https://docs.vulkan.org/spec/latest/chapters/fxvertex.html#VUID-VkVertexInputAttributeDescription-format-00623)"
Apparently, vertex buffers don’t support some VkFormat’s. So I settled for R16_UINT and handled unpacking the vec3 myself in the shader.
Let’s incorporate the bindings into the graphics pipeline’s setup configuration. I keep my functions for creating structures that support rendering organized in methods of a type called RenderingContext.
// vulkan/rendering.rs > impl RenderingContext > new_pipeline(...)
let vertex_binding_descriptions = [
Vertex::binding_description(),
VoxelInstanceParams::binding_description(), // Our new bindings
];
let mut vertex_attribute_descriptions = Vec::<_>::from(Vertex::attribute_descriptions());
let mut voxinst_attribute_descriptions =
Vec::<_>::from(VoxelInstanceParams::attribute_descriptions()); // Our new attributes
vertex_attribute_descriptions.append(&mut voxinst_attribute_descriptions);
let vertex_input_create_info = vk::PipelineVertexInputStateCreateInfo::default()
.vertex_binding_descriptions(&vertex_binding_descriptions)
.vertex_attribute_descriptions(vertex_attribute_descriptions.as_slice());
The vertex_binding_descriptions array is ordered so the location of the description in the array matches up with the .binding(#) binding number the description was assigned upon construction. The vertex/instance buffer(s) of the CmdDraw function we use during command recording must match up with the vertex_binding_descriptions order as well.
Sidenote: Generally, VOXEL EXPLORE intends to capture coherence rules like these and encapsulate them properly with well-thought-out abstractions, while keeping the app’s object graph reasonably intuitive and unfragmented. Structs like
AllocatedDeviceBufferindevice.rsandRenderPassAttachmentsinvulkan/rendering.rsdesign for this philosophy. But asserting categorically perfect, coherence-preserving software design is out of scope for this project, and I will punt the refactor necessary for binding description position coherence to a later devblog.
For reference, this vertex_input_create_info configuration is used to build the VkPipeline, as covered in the Vulkan Tutorial, like so:
// ... more setup of graphics pipeline configuration structs, then
let graphics_pipeline_create_info = vk::GraphicsPipelineCreateInfo::default()
.stages(&shader_stages)
.vertex_input_state(&vertex_input_create_info) // Our updated binding config passed in here
.viewport_state(&viewport_create_info)
// ... other configuration et cetera ...
let pipeline_create_infos = [graphics_pipeline_create_info];
let graphics_pipeline: Vec<vk::Pipeline>;
unsafe {
graphics_pipeline = self
.dev
.create_graphics_pipelines(vk::PipelineCache::null(), &pipeline_create_infos, None)
.unwrap();
}
if !(graphics_pipeline.len() == 1) {
panic!("I thought there would be exactly one graphics pipeline...");
}
return graphics_pipeline[0];
Drawing the instances
We pass the vertex buffer, index buffer, and instance buffer to the VkCommandBuffer recording section of the app’s drawFrame() analogue. In VOXEL EXPLORE’s design, command buffer recording lives in the record_command_buffer method of a RenderingFlow type.
// vulkan/rendering.rs > impl RenderingFlow
fn record_command_buffer(
self: &mut Self,
frameidx: usize,
image_index: u32,
vertex_buffer: &AllocatedDeviceBuffer<Vertex>,
index_buffer: &AllocatedDeviceBuffer<VertexIdx>,
instance_buffer: &AllocatedDeviceBuffer<VoxelInstanceParams>,
) {
//! Called by RenderingFlow::draw_frame_by_index()
// ... resetting the command buffer, configuring the render area, beginning the render pass, etc ...
// Binding and using any other VkPipelines I wanted...
self.dev.cmd_bind_pipeline(
cmd_buffer_target,
vk::PipelineBindPoint::GRAPHICS,
self.pipeline,
);
// Draw this
// Instance buffer in second vertex buffer slot, congruent with binding number (1)
let vertex_buffers: [vk::Buffer; 2] = [vertex_buffer.buffer, instance_buffer.buffer];
// Getting mileage out of the `DataManifest` type I mentioned earlier
let offsets = [
vertex_buffer.manifest.offset_unsigned() as u64,
instance_buffer.manifest.offset_unsigned() as u64,
];
self.dev
.cmd_bind_vertex_buffers(cmd_buffer_target, 0, &vertex_buffers, &offsets);
self.dev.cmd_bind_index_buffer(
cmd_buffer_target,
index_buffer.buffer,
0,
VERTEXIDX_VK_TYPE, // Constant, set to vk::IndexType::UINT16
);
self.dev.cmd_draw_indexed(
cmd_buffer_target, // commandBuffer
index_buffer.manifest.len(), // indexCount
instance_buffer.manifest.len(), // instanceCount
index_buffer.manifest.offset_unsigned(), // firstIndex
vertex_buffer.manifest.offset(), // vertexOffset
0, // firstInstance
);
// Finishing up the render pass...
}
For simplicity, and similary with the Vulkan Tutorial, I use vkCmdDrawIndexed() here, but in practice we will likely transition to vkCmdDrawIndexedIndirectCount() to fanout ‘indirect draws’ for every chunk in a culled buffer without circuiting back to the host every chunk.
The vkCmdDrawIndexed() call has the following parameters in the Vulkan C specification:
void vkCmdDrawIndexed(
VkCommandBuffer commandBuffer,
uint32_t indexCount,
uint32_t instanceCount,
uint32_t firstIndex,
int32_t vertexOffset,
uint32_t firstInstance);
This will instance and draw the vertex geometry inhabiting the bound vertex buffer in the region described by vertexOffset and indexCount. Here, instanceCount is the number of instances of the geometry to draw. firstInstance is a customizable field in case you want the GLSL built-in variable gl_BaseInstance to be something other than 0. gl_InstanceIndex will start at the base value and increment per instance. This is useful in case your geometry is conditional on the instance ID, or you want to pull in associated complementary data (such as chunk attributes) from another buffer in the vertex shader.
Updating the vertex shader
First we add a vertex input attribute with layout location as specced in the VkVertexInputAttributeDescription for our instance binding:
// shader/shader.vert
layout(location = 0) in vec3 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 2) in vec3 inNorm;
layout(location = 3) in uint instanceRelPos; // New, from the instance buffer.
// Advances at a slower rate than the vertex fields above.
Thanks to the VkFormat support stymie I mentioned earlier, we have to unpack the bytes we want ourselves.
// shader/shader.vert > main()
uint instx = uint((instanceRelPos >> 11) & 0x1F);
uint insty = uint((instanceRelPos >> 6) & 0x1F);
uint instz = uint((instanceRelPos >> 1) & 0x1F);
vec3 pos = inPosition + vec3(instx,insty,instz);
Now we are ready to do our typical vertex shader calculations, to compute NDC’s and any other desired values.
// shader/shader.vert > main()
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(pos, 1.0);
Inspecting with RenderDoc
Now that we have the wiring in place, let’s run it in RenderDoc. To follow along, you can find RenderDoc and download for your platform here.
RenderDoc can take captures of running Vulkan frames. These captures let you inspect how the program uses Vulkan, like the state of VkBuffers, and the sequence of API calls. Included in this repository are two saved .rdc captures: one from running the tmasj/voxel-explore repo at tagged commit b25ba8a that does not have instanced drawing, and one from tagged commit e4cde3c that does. These captures can be found under the renderdoc-captures directory, and are included together with the .cap launch settings, and a PNG displaying the RenderDoc inspector GUI. The PNGs for both commits are displayed below. The point of this subsection is to eliminate any guesswork as to how I interpret these .rdc captures.
To use RenderDoc to record frames, build this project with mise run build, and then open RenderDoc. In the Launch Application pane, set the Executable Path to the full path of the build target executable. On Windows that’s X:\path\to\target\debug\voxel-explore.exe. Set Working Directory to the path where you cloned this repo.
Then click ‘…’ by Environment Variables to open a modal that lets you append to PATH and LD_LIBRARY_PATH. Since the VOXEL EXPLORE target executable is not currently redistributable, we need to append the values cargo injects for these environment variables during cargo run. To get these, I just ran VOXEL EXPLORE with this added to the top of the program’s main() function:
// temporarily in main
for (k, v) in std::env::vars() { println!("{k}={v}"); }
Then I searched for PATH and LD_LIBRARY_PATH in the output, and cribbed over the values. This enabled my system to find the needed shared libraries, like from libglfw, from Cargo’s deps/ directory. Once done, the app should launch fine and you can take captures with F12. The good news is, I am already convinced that it’s worth it to teach cargo how to produce a more easily redistributable target executable.
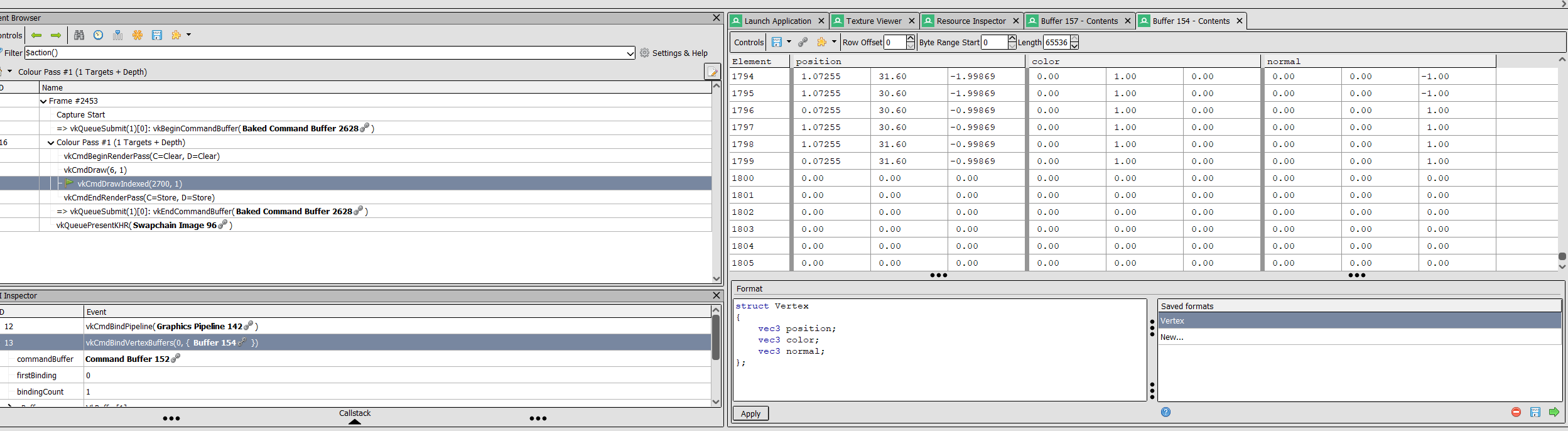
Above is a Renderdoc screenshot that shows the state of the vertex buffer during a running frame of commit b25ba8a. I can, for example, scan to see if the buffer memory has any gaps in it which waste space. In the screenshot above, I opened the Buffer Contents by navigated from the pane for the Buffer resource bound as the vertex buffer (which buffer is which is evident from the associated API call), then clicked “View Contents =>” in the upper right of the panel. The Format field shown takes a DSL that quite looks similar to GLSL to display contents in a human-readable table.
In this first capture, as the screenshot suggests, you can observe that the vertex data fills 1795 rows, almost all of the buffer. Let’s look at the next screenshot, a capture taken from launching version e4cde3c of VOXEL EXPLORE:
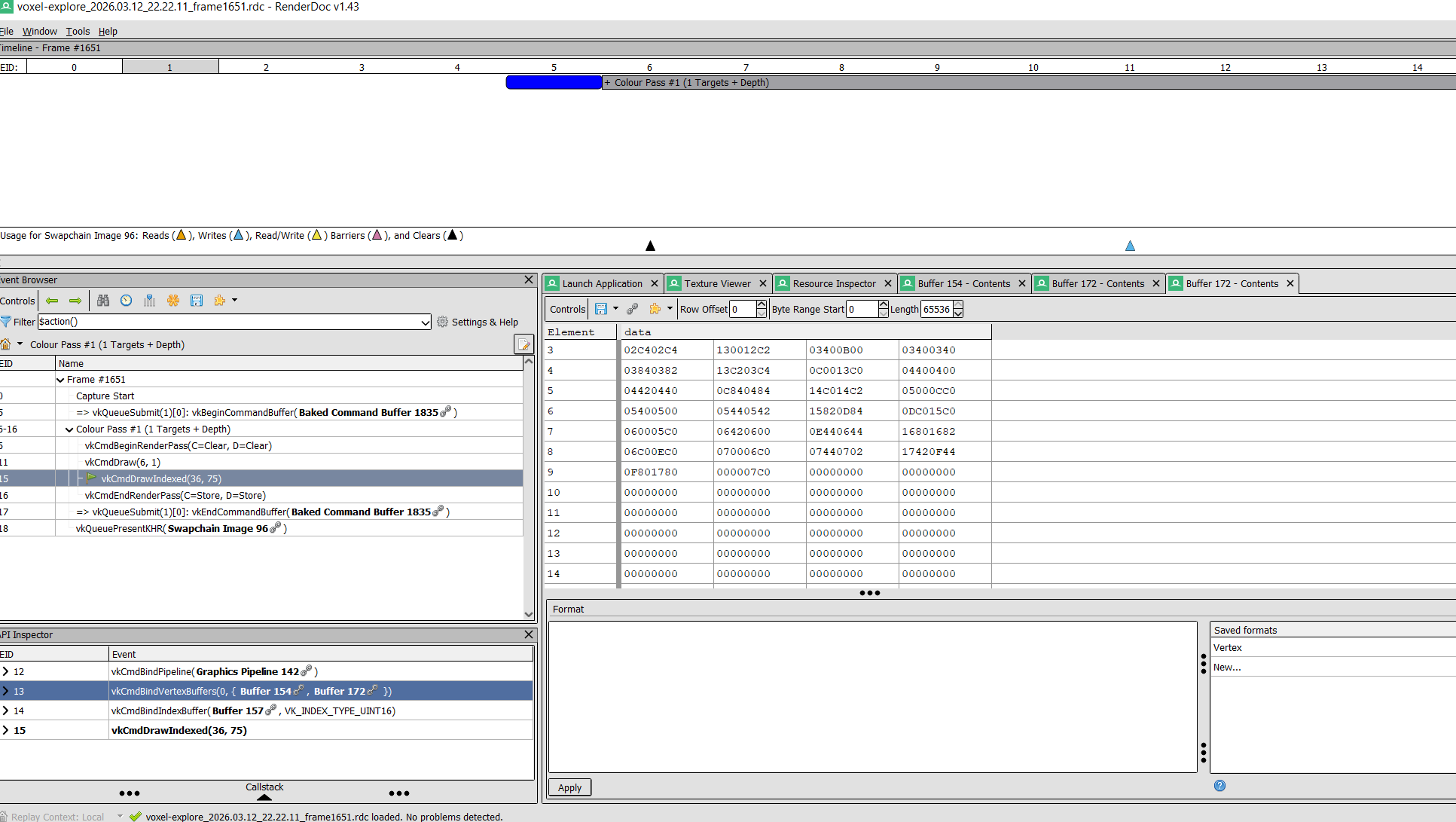
Buffer 172 above is the instance buffer, and Buffer 154 is still the vertex buffer. This capture validates that the new instance buffer is used and sequenced as intended. As the screenshot above suggests, the game geometry of procedural_sculpture_75voxel uses vastly less Buffer space. Granted, the positions of the procedural helix had to be rounded to be cast to integers, producing a somewhat less smooth and aesthetic procedural structure. But, the space savings are worth it. (Remember, fractional voxel offsets are not architecturally ruled out, just outsourced to chunk-level attributes, and I want to show the memory layout of just one chunk here.)
The .rdc capture format is the killer feature here. It can save, share, and compare app rendering flows, which for VOXEL EXPLORE will get more sophisticated over time. Additionally, the captures provide a concrete artifact for what an optimization like instancing offers, so I can review it quickly and don’t need to keep the usefulness of each and every optimization in my head.
4. Alternative instancing technique via SSBOs
There is another instancing architecture that works and is worth mentioning. We can call our selected CmdDraw variant with instanceCount and firstInstance arguments just the same, even without binding an instance buffer. Binding an instance buffer is not a prerequisite for leveraging the instancing loop built into the draw command, nor for using the gl_BaseInstance and gl_InstanceIndex special variables in the vertex shader. If we had a buffer with a random-access array exposed to the vertex shader, then we could use gl_InstanceIndex to index the array for instance data.
We can’t use a UBO to hold this array though, as that is typically capped to a small value which depends on the device. Since the UBO is bound only once per draw, we would need to rebind a small buffer and issue one new draw practically O(number of chunks) times. Individual chunk rendering speeds would then be capped to the host’s clock speed. So, there is another resource descriptor we could use that would be viable and standard for this purpose, called a Shader Storage Buffer Object, which the Vulkan tutorial does cover here. Basically, the buffer needs to have the VK_BUFFER_USAGE_STORAGE_BUFFER_BIT and needs its own DescriptorSetLayoutBinding with the VK_DESCRIPTOR_TYPE_STORAGE_BUFFER descriptor type.
From a logical perspective, this flow is essentially the same as the regular instance buffer approach. But, they express different processes for physically retrieving the vertex data. Instance buffers express a linear, sequential, stride-predictable access pattern that hardware prefetchers are specifically optimized for. Notice that our DescriptorSetLayoutBinding needs a VERTEX shader stage flag in order to be visible to the vertex shader. Vertex, instance, and index buffers, unlike resource descriptors, leverage fixed function hardware that runs before the vertex shader, not pulled during it. This fixed function hardware from a good vendor ideally does a number of useful things:
- Prefetches the vertex, plus any associated instance data
- Keeps an optimal cache line for the data.
- Does any
vec3unpacking and conversions needed using optimized hardware (for a vertex-buffer-compatible format likeR32G32B32_SFLOAT, but sadly unlikeR5G5B5A1_UNORM_PACK16).
To forgo the fixed function hardware would be to forgo the pipelined processing advantages for a hot path like instanced voxels.
There are some qualifications. Realistically, if all we need is to index ssbo.buf[gl_InstanceIndex], which is linear and predictable, then the GPU’s L2 cache would probably have a smart prefetch for us. Using an SSBO does not mean that every access needs to reach all the way back out to VRAM, but keep in mind this cache line competes with any other work going on in the GPU. Also, if the desired memory is at an index that is not in lock-step with our instance index, we need a divisor like ssbo.buf[gl_InstanceIndex / INSTANCES_PER_OBJECT]. This would not be as amenable to a prefetcher. An instance buffer actually provides a structural solution to declaratively express constant divisors just like this, so we can have multiple instance buffers with their own effective input rate, all of which leverage the fixed-function hardware. We can, that is, if the VK_EXT_vertex_attribute_divisor extension is enabled for the VkDevice (Vulkan 1.1+). See this Khronos tutorial for on leveraging fixed-function hardware for vertex divisors and everything else.
The specifics are hardware-dependent, but in principle, in a shader, each pull from random-access memory compounds access latency and risk contention and cache misses. Chunk rendering is to scale for millions or even billions of voxels in a frame. We are not splitting hairs here–even tiny latency inefficiencies compound badly. It is one thing to increase voxel space efficiency by 435 times, but it is another to do so while preserving optimal amortized memory access latency. So, leveraging fixed-function hardware as much as possible is essential.
Architecturally speaking, in our case the instance buffer frees up the firstInstance field for other uses. It can be set to align directly to another object associated with the draw, such as a chunk. No preliminary arithmetic redirection would then be needed on the vertex shader’s side–just a simple and prefetcher-friendly direct index.
5. Next steps for VOXEL EXPLORE chunk design
Our instanced voxels support a chunk design of 32 kibi-voxels in capacity. This is far more than 75 but certainly not optimal. The current design has a few key weaknesses worth calling out. Cards on the table is, I don’t have the fixes on hand, but I will share my thinking about what to do about them.
First big weakness: we do not do anything with the 16th bit of the instance parameter. We could use the bit as a material toggle. Assuming two different materials are compatible with one graphics pipeline and draw call, then we could double dip to have up to two representable materials per chunk, rather than just one. In the best case, this halves the number of chunks we need to load. Further, it would be smart to pair very abundant materials together with very scarce materials, so we minimize chunks carrying just one, rare, free-floating material.
Speaking of sparse chunks–our chunks, when sparse, are mostly empty, wasted space. These gaps are a natural consequence of fixed-size data structures suited to GPU computing. Realistically, we might want to allocate some VRAM for a copy-compaction step to defrag geometry. However, technically, this space isn’t altogether “wasted” if voxels are expected to move, in which case the slack serves as pre-allocated headroom. Probably, it is best to leave the chunk space available for changes, and just rely on compaction for the culled, cached derivative format downstream in the pipline.
Another approach to addressing the gaps would be to make chunks smaller. Though, then we get less benefit from outsourcing to chunk-level attributes, since there would need to be more chunks for the same render distance, so any space advantages would need to be weighed with losses for storing more chunk attributes. Also, remember we already selected Windows minimum allocation size as chunk size. Even if we defined a smaller logical chunk format, we’d still be allocating and uploading 64KiB host buffers before any GPU-side compaction–the OS doesn’t give us finer-grained staging for free. Thirdly, smaller chunk would mean we now overrepresent relative position in the instance parameters unless all positions of our new chunk size could be fully represented in one byte. Fourth, recall that a smaller chunk side length by a factor of $c$ demands $O(c^3)$ more worst-case chunk loads, and this is not a benefit unless each chunk load has commensurately less work to do for a smaller memory region. So, it is possible to reduce chunk size, but the solution would need to consider the ramifications for sparse chunk loading and the format of chunk attributes and instance parameters.
I will leave the unused chunk space thread there for now, since I want to bring up the 1-hot voxel representation again. As I said, the naive dense-matrix approach would not be viable, since most space is empty and we would burn up our GPU cores mostly on 0’s. That said, I will entertain hybrid strategies. There is no law that says one instance parameter set must correspond to exactly one voxel. So, let’s entertain pairing our instance parameters with an extra byte as a 1-hot mask for a sparse octet. Since we want to extract 1 bit from this mask once per voxel instance from the same bitset, we would reuse each set instance parameters 8 times, or once per masking bit. Remember this can be done if we enable the VK_EXT_vertex_attribute_divisor extension to set a VkVertexInputBindingDivisorDescription divisor of 8.
The sparse octet can represent 8 voxels per 3 bytes (2 bytes position + 1 byte bitmask) rather than 1 voxel per 2 bytes, or about a 5.3 times increase in the number of represented voxels per bit, in the best case. This representation only benefits the number of renderable voxels if voxels tend to cluster with their immediate neighbor. That said, if chunks are logically assigned to contiguous volumes, then this volume multiplies by 5 and so reduces chunk loads of dense voxel geometry by a factor of $5^3=125$.
Last remark. Instancing is just one optimization out of hundreds or thousands needed for a great voxel renderer. But it is uniquely convenient as a gateway to begin to understand the tradeoff space and GPU computing in general. High performance graphics computing is an incredibly deep subject. The fun of it comes not from the solutions per se, but from the constraints. There is no silver bullet or single paradigm that solves voxel rendering altogether. Not instancing, SVOs, sparse allocation pooling, SIMD, LOD, special raycasting hardware, or what have you. A good renderer will stack techniques in tandem to compound their benefits. Composition is what voxels are all about, after all!
tmasj